Understanding scikit-learn Classification
This example is an extension of Example 3 where it shows the implementation of all the main Classification models in scikit-learn module, thereby comparing their prediction scores side-by-side. The program also shows the use of the score function of the base classifiers instead of using the accuracy_score function in sklearn.metrics shown in Example 2 and 3.
# Comparing multiple Classifiers
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn.gaussian_process import GaussianProcessClassifier
from sklearn.gaussian_process.kernels import RBF
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier, AdaBoostClassifier
from sklearn.neural_network import MLPClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.discriminant_analysis import QuadraticDiscriminantAnalysis
from sklearn.model_selection import train_test_split
import pandas as pd
classifiers = {
"KNN(3)" : KNeighborsClassifier(3),
"Linear SVM" : SVC(kernel="linear"),
"RBF SVM" : SVC(gamma=2, C=1),
"Gaussian Proc" : GaussianProcessClassifier(1.0 * RBF(1.0)),
"Decision Tree" : DecisionTreeClassifier(max_depth=7),
"Random Forest" : RandomForestClassifier(max_depth=2, n_estimators=10, random_state=0),
"AdaBoost" : AdaBoostClassifier(),
"Neural Net" : MLPClassifier(alpha=1),
"Naive Bayes" : GaussianNB(),
"QDA" : QuadraticDiscriminantAnalysis()
}
file = open('./MyData/gender_data.csv')
data = pd.read_csv(file)
X = data.drop(['gender'], axis=1)
y = data['gender']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.01, random_state=1)
for name, classifier in classifiers.items():
classifier.fit(X_train, y_train)
score = classifier.score(X_test, y_test) * 100
print("{:<15}| score = {:.2f}".format(name, score))
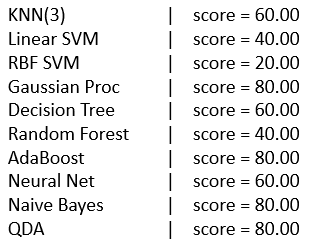
On running this code, the result comes like this: